Data Science Resources
©2020 Symbolix Pty Ltd |
Template by Bootstrapious.com
& ported to Hugo by Kishan B
A night on the tiles
Let’s say you have a data.frame of all the addresses in Victoria (Australia). And it looks like this
library(data.table)
str( dt_households )
Classes ‘data.table’ and 'data.frame': 5502355 obs. of 7 variables:
$ lon : num 144 144 144 144 144 ...
$ lat : num -37.6 -37.6 -37.6 -37.5 -37 ...
$ sa2_name16 : chr "Alfredton" "Alfredton" "Ballarat - South" "Wendouree - Miners Rest" ...
$ sa3_name16 : chr "Ballarat" "Ballarat" "Ballarat" "Ballarat" ...
$ sa4_name16 : chr "Ballarat" "Ballarat" "Ballarat" "Ballarat" ...
$ gcc_name16 : chr "Rest of Vic." "Rest of Vic." "Rest of Vic." "Rest of Vic." ...
$ address_detail_pid: chr "GAVIC424280663" "GAVIC424280663" "GAVIC422148698" "GAVIC423824798" ...
- attr(*, ".internal.selfref")=<externalptr>That’s 5,502,355 addresses, each with lon & lat coordinates, and some ‘areas’ they belong to (SA == “Statistical Area”).
And let’s say you want some way to access this data in a Shiny app, for example our Twin Cities one (demonstrated in this handy video):
The data behind this shiny is currently sitting in an AWS S3 bucket, and we’re using Athena to query it.
And while Athena is great for this specific use-case, the speed of querying the data (it takes about 10 seconds in the video!) is a limitation that I’m hoping TileDB can address.
If you want to find out more about TileDB before we move on you can look it up here (we’ll wait). We are also assuming you have an AWS account (if you want to work alongside this demo).
TileDB and S3
To use S3 through TileDB the first thing you need to do is let tiledb know your AWS region. If you don’t do this step it won’t find the right bucket, and will error.
uri_s3 <- "s3://tiledb-demo/"
cfg <- tiledb::tiledb_config()
cfg["vfs.s3.region"] <- "ap-southeast-2"
ctx <- tiledb::tiledb_ctx(cfg)With that set, to save the data to S3 you can’t (or rather, shouldn’t) simply write the .rds or .csv to S3 and point TileDB to it, that won’t work.
In stead you need to create a TileDB schema, and load that on to S3.
Helpfully there is the handy fromDataFrame() function which does all the hard work for you
tiledb::fromDataFrame(
obj = dt_households ## The data
, uri = uri_s3 ## The location of the schema
, sparse = TRUE ## set TRUE when you data is all different types
## col_index: think of these as SQL indices
, col_index = c("sa4_name16", "lon", "lat")
)Hopefully my comments here are self-explanatory, but here’s a bit more detail on some of them
uri- This is the address of the S3 bucket where your schema will live
sparse = TRUE- In TileDB world there are both dense and sparse arrays .
- Your typical
data.framein R is considered sparse because it usually holds different types of data in each column - For example, in our household data the
lonandlatcolumns are numbers, and the other ones are characters. - A dense array is typically a matrix, where each value is the same type.
col_index- Here you can say which columns of your data you want to index
- You can think of these as SQL indexes; they behave (to the end-user) in the same way
You can view the schema you created by calling schema()
schema <- tiledb::schema( uri_s3 )And if you look at it you’ll see, amongst other things, the Dimensions it has created (these are you indexes).
schema
### Dimension ###
- Name: sa4_name16
- Type: STRING_ASCII
- Cell val num: var
- Domain: null
- Tile extent: null
- Filters: 0
### Dimension ###
- Name: lon
- Type: FLOAT64
- Cell val num: 1
- Domain: [140.966,149.784]
- Tile extent: 9.81869
- Filters: 0
### Dimension ###
- Name: lat
- Type: FLOAT64
- Cell val num: 1
- Domain: [-39.0301,-34.0684]
- Tile extent: 5.96169
- Filters: 0Where’s my data?
If you go to your AWS s3 bucket you’ll see a few files there, but nothing that looks like your household data.
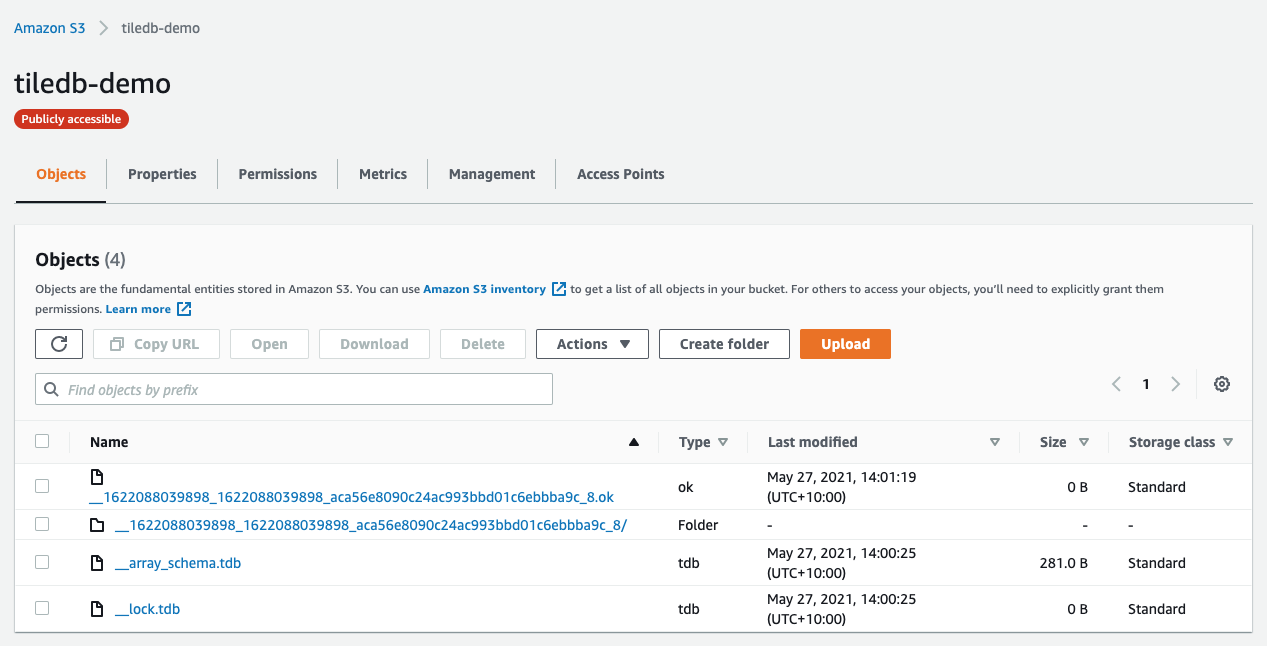
Someone a lot smarter than me can tell you exactly what all the files are for, but from a layman’s perspective (i.e., mine), all I need to know is TileDB has done the hard work of converting my data into a format it understands.
And indeed we can see each column in the data has it’s own .tdb file
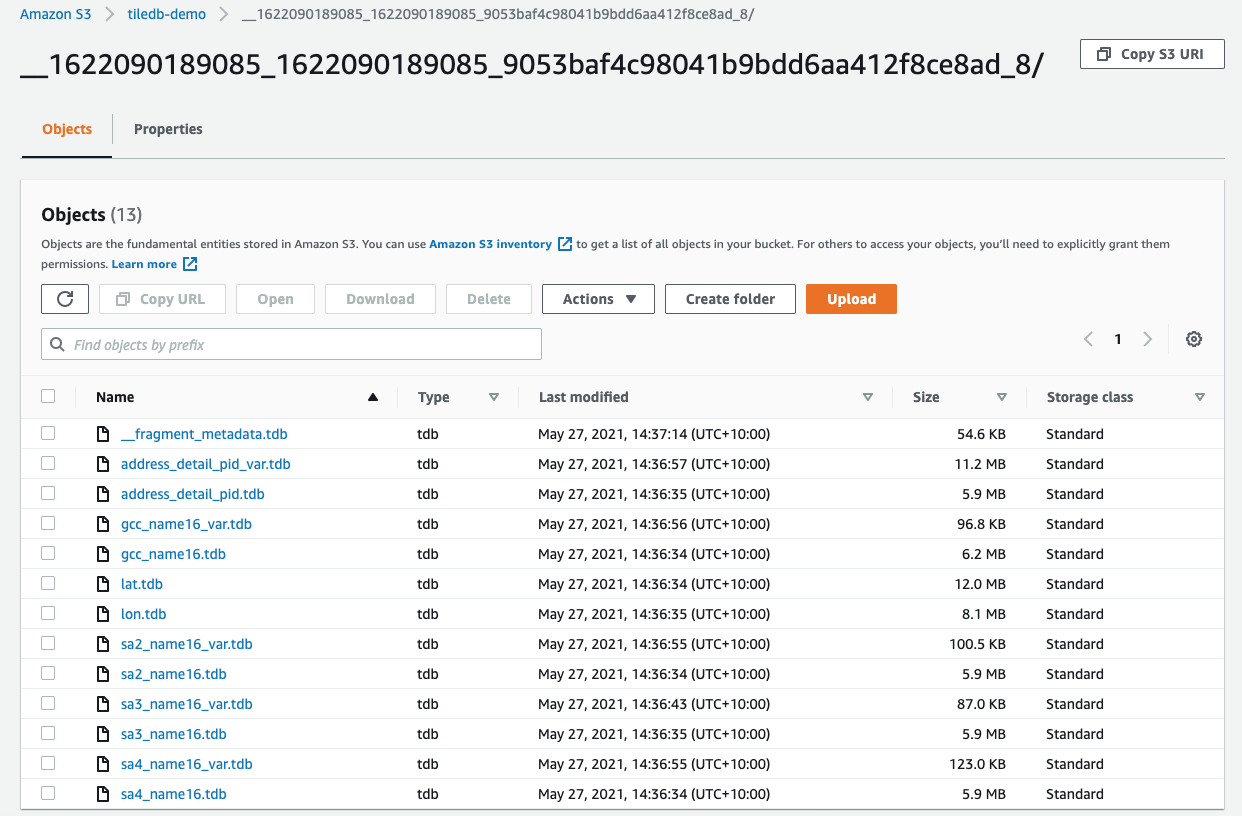
Querying TileDB
The first thing you need to do is create an Array object.
arr <- tiledb::tiledb_array(uri_s3, as.data.frame = TRUE)This doesn’t actually hold any data, but it does point to the data
arr
tiledb_array
uri = 's3://tiledb-demo/'
is.sparse = TRUE
as.data.frame = TRUE
attrs = (none)
selected_ranges = (none)
extended = TRUE
query_layout = (none)
datetimes_as_int64 = FALSE
encryption_key = (none)
timestamp = (none)
as.matrix = FALSEYou can get all the data back out of the Array by ‘subsetting it’
df <- arr[]
head( df )
sa4_name16 sa3_name16 sa2_name16 lon lat gcc_name16
1 Ballarat Ballarat Alfredton 143.6962 -37.53143 Rest of Vic.
2 Ballarat Ballarat Alfredton 143.6964 -37.55797 Rest of Vic.
3 Ballarat Ballarat Alfredton 143.6964 -37.55797 Rest of Vic.
4 Ballarat Ballarat Alfredton 143.6964 -37.55797 Rest of Vic.
5 Ballarat Ballarat Alfredton 143.6982 -37.55781 Rest of Vic.
6 Ballarat Ballarat Alfredton 143.6982 -37.55781 Rest of Vic.
nrow( df )
[1] 5502355This has returned all the data to R. If you want to query only subsets of the data you need to define the ‘ranges’ you want returned.
If you come from a SQL background you would normally write a query like
SELECT *
FROM tbl_household
WHERE lon >= 143.0
AND lon <= 144.0
AND lat >= -38.9
AND lat <= -38.2
;In the TileDB-world you specify the ranges on the array
tiledb::selected_ranges(arr) <- list(
lon = cbind(143.96, 144.1)
, lat = cbind(-38.9, -38.2)
)
arr@selected_ranges
$lon
[,1] [,2]
[1,] 143.96 144.1
$lat
[,1] [,2]
[1,] -38.9 -38.2And now calling the ‘subset’ method will return just those defined ranges
df <- arr[]
head( df )
sa4_name16 sa3_name16 sa2_name16 lon lat gcc_name16
1 Geelong Barwon - West Winchelsea 143.9607 -38.37917 Rest of Vic.
2 Geelong Barwon - West Winchelsea 143.9611 -38.23718 Rest of Vic.
3 Geelong Barwon - West Winchelsea 143.9611 -38.23718 Rest of Vic.
4 Geelong Barwon - West Winchelsea 143.9611 -38.24019 Rest of Vic.
5 Geelong Barwon - West Winchelsea 143.9611 -38.24019 Rest of Vic.
6 Geelong Barwon - West Winchelsea 143.9611 -38.24019 Rest of Vic.
nrow( df )
[1] 4232Which matches our original data
dt_households[
lon >= 143.96 & lon <= 144.1 &
lat >= -38.9 & lat <= -38.2
][
, .N ## in data.table, .N == base::nrow() == dplyr::n()
]
[1] 4232And here’s an example using a character column in the query. However, a quirk with constructing this query is you need to use the same values twice.
m <- matrix(
data = c(
rep("Melbourne - Inner", 2)
, rep("Melbourne - South East", 2)
)
, ncol = 2
, byrow = T
)
tiledb::selected_ranges(arr) <- list(
sa4_name16 = m
)
df <- arr[]
head( df )
sa4_name16 sa3_name16 sa2_name16 lon lat gcc_name16
1 Melbourne - Inner Brunswick - Coburg Brunswick 144.9488 -37.76973 Greater Melbourne
2 Melbourne - Inner Brunswick - Coburg Brunswick 144.9488 -37.76973 Greater Melbourne
3 Melbourne - Inner Brunswick - Coburg Brunswick 144.9489 -37.76987 Greater Melbourne
4 Melbourne - Inner Brunswick - Coburg Brunswick 144.9489 -37.76987 Greater Melbourne
5 Melbourne - Inner Brunswick - Coburg Brunswick 144.9491 -37.77546 Greater Melbourne
6 Melbourne - Inner Brunswick - Coburg Brunswick 144.9491 -37.77542 Greater Melbourne
unique( df$sa4_name16 )
[1] "Melbourne - Inner" "Melbourne - South East"
nrow( df )
[1] 1247517
dt_households[
sa4_name16 %in% unique( as.vector( m ) )
][
, .N
]
[1] 1247517Comparison with Athena
In the Twin Cities shiny I mentioned earlier , the user queries the data by drawing a box on an area of the map.
So let’s replicate that here, but using a TileDB query
system.time({
## Get a bounding box defined by the area drawn on the map
bbox <- "POLYGON ((144.941682853975 -37.8653772844753, 144.994640388765 -37.8653772844753, 144.994640388765 -37.8339979685181, 144.941682853975 -37.8339979685181, 144.941682853975 -37.8653772844753))"
bbox <- wk:::st_as_sfc.wk_wkt( wk::wkt( bbox ) )
bbox <- sf::st_bbox( bbox )
## construct the tileDB range query
m <- matrix( bbox, ncol = 2, byrow = F )
tiledb::selected_ranges(arr) <- list(
lon = m[1, , drop = FALSE]
, lat = m[2, , drop = FALSE ]
)
## extract the data
df <- arr[]
})
user system elapsed
0.392 0.079 0.667
nrow( df )
[1] 58217The query time of ~0.4 seconds is pretty impressive. It may be that I’ve run this query more than once and it has cleverly cached the results, but for now I think it’s a good note on which to end this post.
In the not too distant future I plan to do a more thorough benchmark and comparison between Athena, Postgres, MongoDB and TileDB, but for now I’m going to stop here and live in blissful un-awareness of things I may have got wrong, and just assume all my shiny apps from now on will be super-responsive!
Thanks go to Dirk Eddelbuettel for showing me the ropes and getting me started with TileDB.
Cover photo by Photo by Maria Lupan on Unsplash